在前一篇文章中,我們討論了如何進行特徵創建、轉換和縮放。然而,隨著特徵的增加,模型可能變得過於複雜且容易過擬合。這時,我們需要進行特徵選擇,以確保只使用對模型預測最有幫助的特徵,並提高模型的性能和解釋性。完成後,我們也要將數據分割為訓練集和測試集,這是評估模型性能的重要步驟。
由於我們之前已採用 One Hot Encoding 方式將特徵擴增,為了避免一些不重要的參數影響,我們需要進行特徵選擇。這包括之前提過的 Pearson 係數、卡方檢驗(Chi-squared)、遞歸特徵消除法(RFE),以及嵌入法(Embedded methods),這些方法涉及不同的演算法,如邏輯回歸、隨機森林等。筆者喜好將這些都計算完並放在 DataFrame 裡一次比較。首先要先拆分 X 和 y,以確保程式知道輸入和輸出分別是什麼,才能了解它們之間的關係。程式碼如下:
X = cleaning_data_filtered.drop('Test Results', axis=1) # 我們要預測 Normal/Abnirmal,這些都是輸出,所以要把這個欄位移除才是輸入
y = cleaning_data_filtered['Test Results'] # 輸出是 Test Results
接下來,我們將使用不同的方法來進行特徵選擇:
這個方法通過計算每個特徵 X 與目標變量 y 的相關性來篩選特徵。以下是相應的程式碼:
import numpy as np
def cor_selector(X, y,num_feats):
cor_list = []
feature_name = X.columns.tolist()
# 計算每個特徵與 y 的相關性
for i in X.columns.tolist():
cor = np.corrcoef(X[i], y)[0, 1]
cor_list.append(cor)
# 將 NaN 替換為 0
cor_list = [0 if np.isnan(i) else i for i in cor_list]
# 篩選出相關性最高的特徵
cor_feature = X.iloc[:,np.argsort(np.abs(cor_list))[-num_feats:]].columns.tolist()
# 特徵篩選 0 不選擇, 1 選擇
cor_support = [True if i in cor_feature else False for i in feature_name]
return cor_support, cor_feature
cor_support, cor_feature = cor_selector(X, y, 12)
print(str(len(cor_feature)), 'selected features')
使用卡方檢驗來評估每個特徵的顯著性:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
X_norm = MinMaxScaler().fit_transform(X)
chi_selector = SelectKBest(chi2, k=12)
chi_selector.fit(X_norm, y)
chi_support = chi_selector.get_support()
chi_feature = X.loc[:,chi_support].columns.tolist()
print(str(len(chi_feature)), 'selected features')
這個方法利用一個基於邏輯回歸的模型,通過遞歸地消除最不重要的特徵來選擇特徵:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
rfe_selector = RFE(estimator=LogisticRegression(), n_features_to_select=12, step=10, verbose=5)
rfe_selector.fit(X_norm, y)
rfe_support = rfe_selector.get_support()
rfe_feature = X.loc[:,rfe_support].columns.tolist()
print(str(len(rfe_feature)), 'selected features')
使用邏輯回歸和隨機森林進行嵌入法特徵選擇:
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
embeded_lr_selector = SelectFromModel(LogisticRegression(penalty="l2"), max_features=12)
embeded_lr_selector.fit(X_norm, y)
embeded_lr_support = embeded_lr_selector.get_support()
embeded_lr_feature = X.loc[:,embeded_lr_support].columns.tolist()
print(str(len(embeded_lr_feature)), 'selected features')
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
embeded_rf_selector = SelectFromModel(RandomForestClassifier(n_estimators=100), max_features=12)
embeded_rf_selector.fit(X, y)
embeded_rf_support = embeded_rf_selector.get_support()
embeded_rf_feature = X.loc[:,embeded_rf_support].columns.tolist()
print(str(len(embeded_rf_feature)), 'selected features')
最後,我們將所有特徵選擇方法的結果彙總在一起,以便進行比較:
feature_name = X.columns
# 將所有選擇的結果放在 DataFrame 中
feature_selection_df = pd.DataFrame({'Feature':feature_name, 'Pearson':cor_support, 'Chi-2':chi_support, 'RFE':rfe_support, 'Logistics':embeded_lr_support,
'Random Forest':embeded_rf_support})
# 計算每個特徵被選擇的次數
# 在加總數量時先轉換 Boolean 為 integer
feature_selection_df['Total'] = feature_selection_df[['Pearson', 'Chi-2', 'RFE', 'Logistics', 'Random Forest']].astype(int).sum(axis=1)
# 排序顯示前 12 個特徵 (可以嘗試顯示不同的特徵數)
feature_selection_df = feature_selection_df.sort_values(['Total','Feature'] , ascending=False)
feature_selection_df.index = range(1, len(feature_selection_df)+1)
feature_selection_df.head(12)
得出的結果: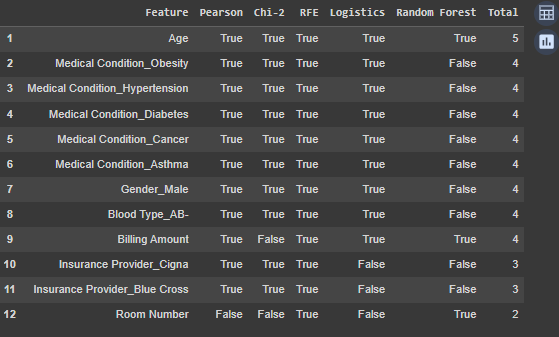
結果解釋
總選擇次數反映了每個特徵在不同特徵選擇方法中的重要性。例如,Age 特徵被所有五種方法選擇,表明它對預測目標變數極其重要。
方法分析:
Pearson:所有特徵中,大部分都被認為與目標變數有線性關聯,只有 Room Number 未被選中,這顯示出其與目標變數之間的相關性較弱。Chi-2:所有與健康狀況相關的特徵和 Gender_Male 被選中,表示這些特徵對於類別預測具有顯著性。RFE (遞歸特徵消除法):大多數特徵在此方法中也被選中,顯示它們對於模型的預測準確性具有影響力。Logistics:雖然大部分特徵在此方法中被選中,但 Insurance Provider_Cigna 和 Insurance Provider_Blue Cross 未被選中,可能表明它們在預測中相對不重要。Random Forest:此方法強調特徵的重要性,Room Number 被選中,但它在其他方法中未顯示重要性,顯示出這個特徵在某些模型中可能對預測有所幫助。特徵重要性:
Age 是最重要的特徵,因為它被所有五種方法選中,建議保留。Medical Condition 相關的特徵(如 Obesity、Hypertension 等)在大多數方法中都顯示出高重要性,值得在模型中保留。Billing Amount 在多數方法中被選中,可能與預測結果有關聯。Room Number 僅在少數方法中被選中,重要性較低,可能可以考慮移除。筆者決定嘗試在模型訓練前將 Room Number 特徵刪除,並保留其他特徵。因此:
cleaning_data_filtered.drop('Room Number', axis=1, inplace=True)
最終在建立演算法之前,最重要的一步是切分數據集
隨機切分法是最常見的數據切分方法,通常將數據按照 7:3 或 8:2 的比例分為訓練集和測試集。以 7:3 切分的程式碼如下,random_state 設定任意數值,目的是為了後續要跟模型進行比較時,可以確保切分後運用的數據是一樣的。若讀者沒有要用不同模型進行比較時,可以不需設定 random_state。
from sklearn.model_selection import train_test_split
# 將數據分為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
在類別不平衡的數據集中,分層抽樣法可以確保訓練集和測試集中的每個類別比例一致,這樣可以避免模型在某些類別上表現過於偏差。程式碼如下:
# 分層抽樣切分數據
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
注意:除了上述方法,還有更複雜的驗證方法,如K-fold交叉驗證。這種方法在模型選擇和評估階段特別有用,我們將在後續的模型訓練和評估章節中介紹。
由於此 Kaggle 數據集類別是平衡的,筆者將採用隨機切分法來進行。
通過特徵選擇,我們可以提高模型的效率和解釋性;通過適當的數據切分,我們可以確保模型評估的可靠性和泛化能力🌍。在實際應用中,我們需要根據具體的數據特性和問題需求,選擇合適的特徵選擇方法和數據切分策略🎯。這個階段也是需要嘗試不同的組合,包含特徵數量及不同方法🔧。接下來,我們將進入演算法選擇和模型訓練的階段,利用我們精心準備的數據集來構建預測模型🚀💻。


 iThome鐵人賽
iThome鐵人賽